Основы компиляции
Программы, написанные на языках программирования высокого уровня перед выполнением на ЭВМ должны транслироваться в эквивалентные программы, написанные на машинном коде.
Транслятор - это программа, которая переводит исходную программу в эквивалентную ей объектную программу.
Если исходный язык является языком высокого уровня, например таким, как Паскаль, С++, и если объектный язык - автокод, то такой транслятор называется компилятором.
Интерпретатор для некоторого исходного языка принимает исходную программу, написанную на этом языке, как входную информацию и выполняет ее. Различие между компилятором и интерпретатором состоит в том, что интерпретатор не порождает объектную программу, которая затем должна выполняться, а непосредственно выполняет ее сам.
Для того чтобы выяснить, как осуществить выполнение инструкций исходной программы, чистый интерпретатор анализирует ее всякий раз, когда она должна быть выполнена. Конечно же, это не эффективно и используется не очень часто.
При программировании интерпретатор обычно разделяют на две фазы. На- первой фазе интерпретатор анализирует всю исходную программу, почти так же, как это делает компилятор, и транслирует ее в некоторое внутреннее представление. На второй фазе это внутреннее представление исходной программы интерпретируется или выполняется. Внутреннее представление исходной программы разрабатывается для того, чтобы свести к минимуму время, необходимое для расшифровки или анализа каждой инструкции при ее выполнении.
Для компиляции компилятор должен выполнить анализ исходной программы,, а затем синтез объектной программы.
Сначала исходная программа разлагается на ее составные части; затем из них строятся части эквивалентной объектной программы. Для этого на этапе анализа компилятор строит несколько таблиц, которые используются затем как при анализе, так и при синтезе.
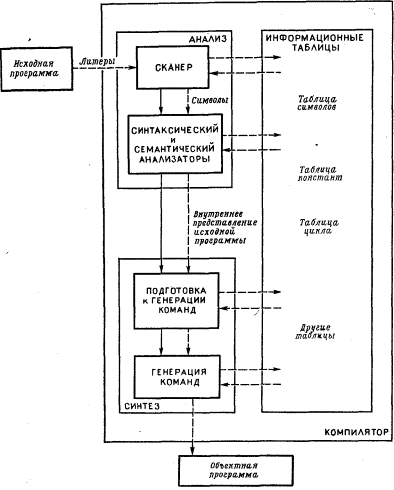 |
Информационные таблицы.
При анализе программы из описаний, заголовков процедур, заголовков циклов и т.д. извлекается информация и сохраняется для последующего использования. Эта информация обнаруживается в отдельных точках программы и организуется так, чтобы к ней можно было обратиться из любой части компилятора. Например, при каждом использовании идентификатора необходимо знать, как был описан этот идентификатор и как он использовался в других местах программы. Что конкретно следует хранить, зависит, конечно, от исходного языка, объектного языка и сложности компилятора. Но в каждом компиляторе в той или иной форме используется таблица символов (иногда ее называют списком идентификаторов или таблицей имен). Это таблица идентификаторов, встречающихся в исходной программе, вместе с их атрибутами. К атрибутам относятся тип идентификатора, его адрес в объектной программе и любая другая информация о нем, которая может понадобиться при генерации объектной программы.
Сканер
Сканер - самая простая часть компилятора, иногда также называемая лексическим анализатором. Сканер просматривает литеры исходной программы слева направо и строит символы программы - целые числа, идентификаторы, служебные слова и т. д. (Символы передаются затем на обработку фактическому анализатору.) На этой стадии может быть исключен комментарий. Сканер также может заносить идентификаторы в таблицу символов и выполнять другую простую работу, которая фактически не требует анализа исходной программы. Он может выполнить большую часть работы по макрогенерации в тех случаях, когда требуется только текстовая подстановка.
Обычно сканер передает символы анализатору во внутренней форме. Каждый разделитель (служебное слово, знак операции или знак пунктуации) будет представлен целым числом. Идентификаторы или константы можно представить парой чисел. Первое число, отличное от любого целого числа, использующегося для представления разделителя, характеризует сам "идентификатор" или "константу"; второе число является адресом или индексом идентификатора или константы в некоторой таблице. Это позволяет в остальных частях компилятора работать эффективно, оперируя с символами фиксированной длины, а не с цепочками литер переменной длины.
Синтаксический и семантический анализаторы
Эти анализаторы выполняют действительно сложную работу по расчленению исходной программы на составные части, формированию ее внутреннего представления и занесению информации в таблицу символов и другие таблицы. При этом также выполняется полный синтаксический и семантический контроль программы.
Синтаксис - способ соединения слов (и их форм) в словосочетания и предложения.
Семантика - это значения единиц языка.
Обычный анализатор представляет собой синтаксически управляемую программу. В действительности стремятся отделить синтаксис от семантики настолько, насколько это возможно. Когда синтаксический анализатор (распознаватель) узнает конструкцию исходного языка, он вызывает соответствующую семантическую процедуру, или семантическую программу, которая контролирует данную конструкцию с точки зрения семантики и затем запоминает информацию о ней в таблице символов или во внутреннем представлении программы. Например, когда распознается описание переменных, семантическая] программа проверяет идентификаторы, указанные в этом описании, чтобы убедиться в том, что они не были описаны дважды, и заносит их вместе с атрибутами в таблицу символов.
Когда встречается инструкция
присваивания вида
<переменная>:= <выражение>
семантическая программа проверяет
переменную и выражение на соответствие
типов и затем заносит инструкцию
присваивания в программу во внутреннем
представлении.
Внутреннее представление исходной программы
Внутреннее представление исходной программы в значительной степени зависит от его дальнейшего использования. Это может быть дерево, отражающее синтаксис исходной программы. Это может быть исходная программа, в так называемой польской записи, список тетрад и т.д.
Подготовка к генерации команд
Перед генерацией команд обычно необходимо некоторым образом обработать и изменить внутреннюю программу. Кроме того, должна быть распределена память под переменные готовой программы. Одним, из важных моментов на этом этапе является оптимизация программы с целью уменьшения времени ее работы.
Генерация команд
По существу, на этом этапе происходит перевод внутреннего представления исходной программы на автокод или на машинный язык. Это, по-видимому, наиболее хлопотная и кропотливая часть компилятора, хотя и наиболее понятная.
В интерпретаторе эта часть компилятора
заменяется программой, которая фактически
выполняет (или интерпретирует) внутреннее
представление исходной программы. Причем
само внутреннее представление в этом
случае мало чем отличается от того, которое
получается при компиляции.
Естественно, возникает вопрос: в чем
заключаются главные трудности реализации
компилятора? Сканер - весьма прост и хорошо
изучен. Синтаксические анализаторы, если
речь идет о простых формальных языках,
также довольно хорошо изучены. В
действительности эту часть можно в
значительной степени автоматизировать. (С
тех пор, как синтаксис был формализован,
большинство исследований по созданию
компиляторов касалось именно синтаксиса, а
не семантики.) Наиболее трудными и
запутанными частями компилятора являются
семантический анализ, программы подготовки
генерации и программы генерации команд. Эти
три части взаимозависимы, должны в
значительной степени разрабатываться
совместно и могут коренным образом
измениться при переходе с одного
объектного языка на другой или с одной
машины на другую.
Давайте обсудим основные элементы процесса компиляции. Начнем с исходного текста программы.
Алфавит - система неразложимых, уверенно отличимых друг от друга символов (букв, цифр, знаков препинания и др. символов), используемых для построения языков программирования.
Язык программирования можно задать:
перечислив все цепочки символов;
|
написав программу-распознаватель,
которая получает на вход цепочку
символов и выдает ответ "да", если
цепочка принадлежит языку и "нет" в
противном случае;
|
с помощью механизма порождения -
грамматики. | |
Чтобы задать грамматику, требуется указать:
множество символов алфавита (или
терминальных символов)
|
множество нетерминальных символов
(или
метасимволов), не пересекающееся с
терминальными символами
|
множество правил вывода,
определяющих
правила подстановки для цепочек | |
На практике применяется также другая форма записи, традиционно называемая нормальными формами Бэкуса-Наура (НФБН). Терминалы в НФБН записываются как обычные символы алфавита, а нетерминалы - как имена в угловых скобках <>.
Например, грамматику целых чисел без знака можно записать в виде:
<число> : <цифра> | <цифра> <число>
<цифра> : 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Рассмотрим язык простейших арифметических формул:
<формула> : (<формула>) | <число> |
<формула><знак><формула>
<знак> : + | *
Почему "3+5*2" является формулой?
Приведем последовательность
преобразований цепочек (так называемый
"разбор"
или "вывод"):
Если в процессе вывода цепочки правила грамматики применяются только к самому левому нетерминалу, говорят, что получен левый вывод цепочки. Аналогично определяется правый вывод.
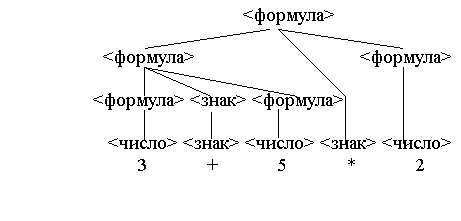 |
Изобразим выполняемые замены цепочек в виде т.н. "дерева разбора" (или дерева вывода).
Одно и то же дерево разбора может описывать различные выводы (в дереве не фиксирован порядок применения правил). Однако, между левыми (или правыми) выводами и деревьями разбора для цепочек существует однозначное соответствие.
Во время синтаксического анализа предложения исходной программы распознаются как языковые конструкции, описываемые используемой грамматикой. Этот процесс можно рассматривать как построение дерева грамматического разбора для транслируемых предложений.
Методы грамматического разбора можно разбить на 2 больших класса - восходящие и нисходящие - в соответствии с порядком построения дерева грамматического разбора. Нисходящие методы (методы сверху вниз) начинают с правила грамматики, определяющего конечную цель анализа с корня дерева грамматического разбора и пытаются его наращивать, чтобы последующие узлы дерева соответствовали синтаксису анализируемого предложения. Восходящие методы (методы снизу вверх) начинают с конечных узлов дерева грамматического разбора и пытаются объединить их построением узлов все более и более высокого уровня до тех пор, пока не будет достигнут корень дерева.
Мы рассмотрим пока 2 метода разбора (восходящий и нисходящий): метод операторного предшествования и рекурсивного спуска.
Метод операторного предшествования
Он основан на анализе пар последовательно расположенных операторов исходной программы и решении вопроса о том, какой из них должен выполняться первым.
Рассмотрим, например, арифметическое
выражение
А + В * С - D
В соответствии с обычными правилами
арифметики умножение и деление
осуществляются до сложения и вычитания.
Можно сказать, что умножение и деление
имеют более высокий уровень
предшествования, чем сложение и вычитание.
При анализе первых двух операторов (+ и *)
выяснится, что оператор + имеет более низкий
уровень предшествования, чем оператор *.
Часто это записывают следующим образом
+ <• *
Аналогично для следующей пары операторов (*
и -) оператор * имеет более высокий уровень
предшествования, чем оператор -. Мы можем
записать это в виде
* •> -
Метод операторного предшествования
использует подобные отношения между
операторами для управления процессом
грамматического разбора. В частности, для
рассмотренного арифметического выражения
мы получили следующие отношения
предшествования:
A+B*C-D
<• •>
Отсюда следует, что подвыражение В*С должно
быть вычислено до обработки любых других
операторов рассматриваемого выражения. В
терминах дерева грамматического разбора
это означает, что операция * расположена на
более низком уровне узлов дерева, чем
операции + или -. Таким образом,
рассматриваемый метод грамматического
разбора должен распознать конструкцию В* С,
интерпретируя ее в терминах заданной
грамматики, до анализа соседних термов
предложения.
Предшествующее изложение иллюстрирует основную идею, на которой основан метод грамматического разбора, построенный на отношениях операторного предшествования.
В рамках этого метода анализируемое предложение сканируется слева направо до тех пор, пока не будет найдено подвыражение, операторы которого имеют более высокий уровень предшествования, чем соседние операторы. Далее это подвыражение распознается в терминах правил вывода используемой грамматики. Этот процесс продолжается до тех пор, пока не будет достигнут корень дерева, что и будет означать окончание процесса грамматического разбора.
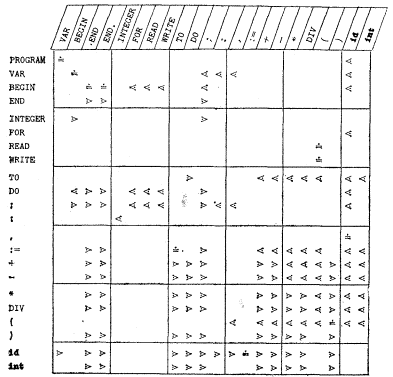 |
Применим эту таблицу к оператору программы
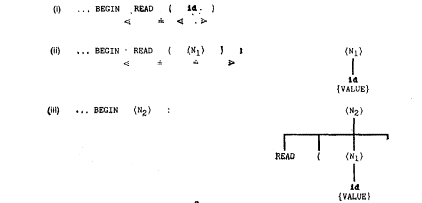 |
Рекурсивный спуск
Процессор грамматического разбора, основанный на этом методе, состоит из отдельных процедур для каждого нетерминального символа, определенного в грамматике. Каждая такая процедура старается во входном потоке найти подстроку, начинающуюся с текущей лексемы, которая может быть интерпретирована как нетерминальный символ, связанный с данной процедурой. В процессе своей работы она может вызывать другие подобные процедуры или даже рекурсивно саму себя для поиска других нетерминальных символов. Если эта процедура находит соответствующий нетерминальный символ, то она заканчивает свою работу, передает в вызвавшую ее программу признак успешного завершения и устанавливает указатель текущей лексемы на первую лексему после распознанной подстроки. Если же процедура не может найти подстроку, которая могла бы быть интерпретирована как требуемый нетерминальный символ, она заканчивается с признаком неудачи или же вызывает процедуру выдачи диагностического сообщения и процедуру восстановления.
Пусть дана грамматика
<id_list>:=id{, id}
<read>: READ (<id_list>)
Пусть сканер возвращает следующие коды лексемам
| Лексема | Код |
| READ | 8 |
| ( | 20 |
| ) | 21 |
| Id | 22 |
Тогда программа будет иметь вид
function read: boolean;
begin
found:=false;
if token=8 {Read} then
begin
{перейти к следующей лексеме}
if token=20 {(} then
begin
{перейти к следующей лексеме}
if IDLIST закончилась успешно then
if token=21 {)} then
begin
found:=true;
{перейти к следующей лексеме}
end;
end;
end;
if found=true then
{успешное завершение}
else
{неудачное завершение}
end;
function IDLIST: boolean;
begin
found:=false;
if token=22 {id} then
begin
found:=true;
{перейти к следующей лексеме}
while (token=14{,} and (found=true)) do
begin
{перейти к следующей лексеме}
if token=22{id} then
{перейти к следующей лексеме}
else
found:=false;
end;
end;
if found=true then
{успешное завершение}
else
{неудачное завершение}
end;
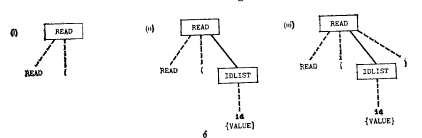 |
Какой же кода не хватает при успешном завершении вышеописанных процедур? При успешном завершении происходит представление программы в некоторой промежуточной форме.
Промежуточная форма представления программы.
Польская запись.
Для представления арифметических и логических выражений часто используется польская запись, которая просто и точно указывает порядок выполнения операций. Кроме того, она не требует скобок. В этой записи, впервые примененной польским логиком Я. Лукашевичем, операторы следуют непосредственно за операндами. Поэтому ее иногда называют постфиксной записью. Классическая форма записи, как мы обычно пишем, называется инфиксной.
A*B --> AB*
A*B+C-->AB*C+
A*(B+C/D)-->ABCD/+*
A*B+C*D-->AB*CD*+
Правила представления в польской записи:
1) Идентификаторы следуют в том же порядке,
что и в инфиксной записи
2) Операторы следуют в том же порядке, в
каком они должны вычисляться(слева направо)
3) Операторы располагаются непосредственно
за своими операндами.
Перевод из постфиксную запись
осуществляется при помощи стека.
5 * ( ( (9 + 8) * (4 * 6) ) + 7)
push(5)
push(9)
push(8)
push(pop+pop)
push(4)
push(6)
push(pop*pop)
push(pop*pop)
push(7)
push(pop+pop)
push(pop*pop)
writeln(pop)
Метод четверок.
Каждая четверка записывается в виде
операция, op1, op2, результат,
где операция - это выполняемая объектным
кодом функция
op1, op2 - операнды этой операции
Например,
(-a+b)*(c+d)
будет соответствовать такой
последовательности четверок
- a, 1
+ 1, b 2
+ c, d 3
* 2, 3, 4
Из сформированных четверок нетрудно
сгенерировать машинный код.
Итак, на сегодняшнем занятии мы рассмотрели основы компиляции.